MetaPhlAn 4—宏基因组物种注释工具
今天为大家带来一款非常新的,但是功能非常强大的生信分析工具– MetaPhlAn 4.2.2。

MetaPhlAn是一种计算工具,用于从元基因组霰弹枪测序数据(即非16S)也就是宏基因组数据中分析物种级微生物群落(细菌、古细菌和真核生物)的组成。最新版的MetaPhlAn 4发表在2023年2月23日《Nature Biotechnology》期刊上。MetaPhlAn 4利用已知微生物基因组和MAGs的组合扩展集,定义了物种水平上的基因组箱(SGBs),以进行更全面的宏基因组分类学分析。从101万个原核生物参考基因组和宏基因组组装基因组的集合中,在物种水平为26970个基因组箱定义了特异性的标记基因,其中4992个在物种水平上尚未分类。MetaPhlAn 4在全球人类肠道微生物中增加了约20%的短序列物种注释,而在尚未充分研究的环境(如反刍动物瘤胃微生物组等)中增加了40%。MetaPhlAn 4在综合评估分析方面比现有可替代方案更准确,同时还可以对未培养分离的生物体进行准确定量。总而言之,MetaPhlAn 4是宏基因组物种注释中一个方便而且准确的最新工具。
接下来就为大家带来MetaPhlAn 4的安装和使用教程,下面的操作都要在服务器上进行,如果没有服务器,那也没法啦。
一、创建conda环境
github官网教程:https://github.com/biobakery/MetaPhlAn/wiki/MetaPhlAn-4
创建一个名叫mpa的环境
二、安装metaphlan4
mamba create -n metaphlan4 -c conda-forge -c bioconda metaphlan=4.2.2
conda activate metaphlan4
这一步可能会安装很久,有时候可能会出现安装不上的问题,这时候我们可以用pip来安装。
metaphlan --version如果可以正确显示版本信息,则安装成功。
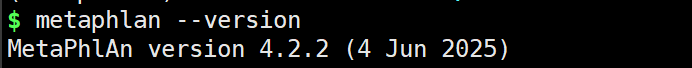
三、安装数据库
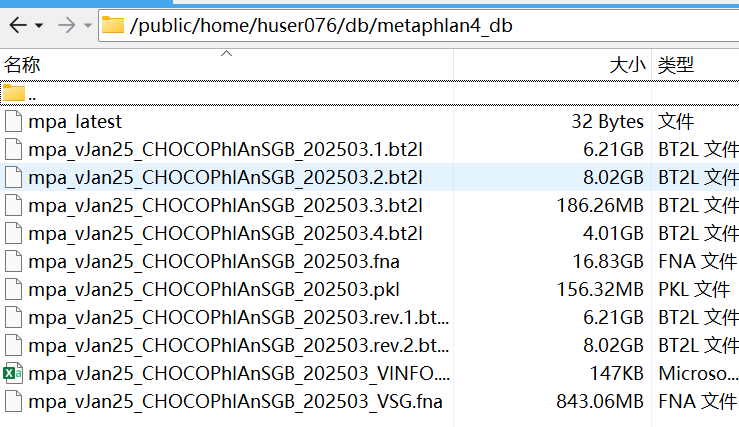
默认情况下可以使用metaphlan --install命令可以安装数据库,按照官方建议添加--db_dir 参数,并指定conda目录外的专用数据库目录/mnt/metaphlan4_db,大家按需求修改。指定conda外目录的好处就是conda环境目录容量小一些,重新安装时还可以设置此目录作为数据库目录就行,不用重新下载和配置了。
metaphlan --install --db_dir /public/home/huser076/db/metaphlan4_db
# MetaPhlAn自动下载的数据库有可能不是最新的,大家可以清空指定文件夹,
# 或将已有数据文件全部移到其他备份目录
# 然后编辑一个mpa_latest
cd /mnt/metaphlan4_db
vim mpa_latest
mpa_vJun23_CHOCOPhlAnSGB_202307
## 这个文件不要有空格不要有空行,就单独这个版本的名称独占一行即可安装完成之后是这下面的 样子:
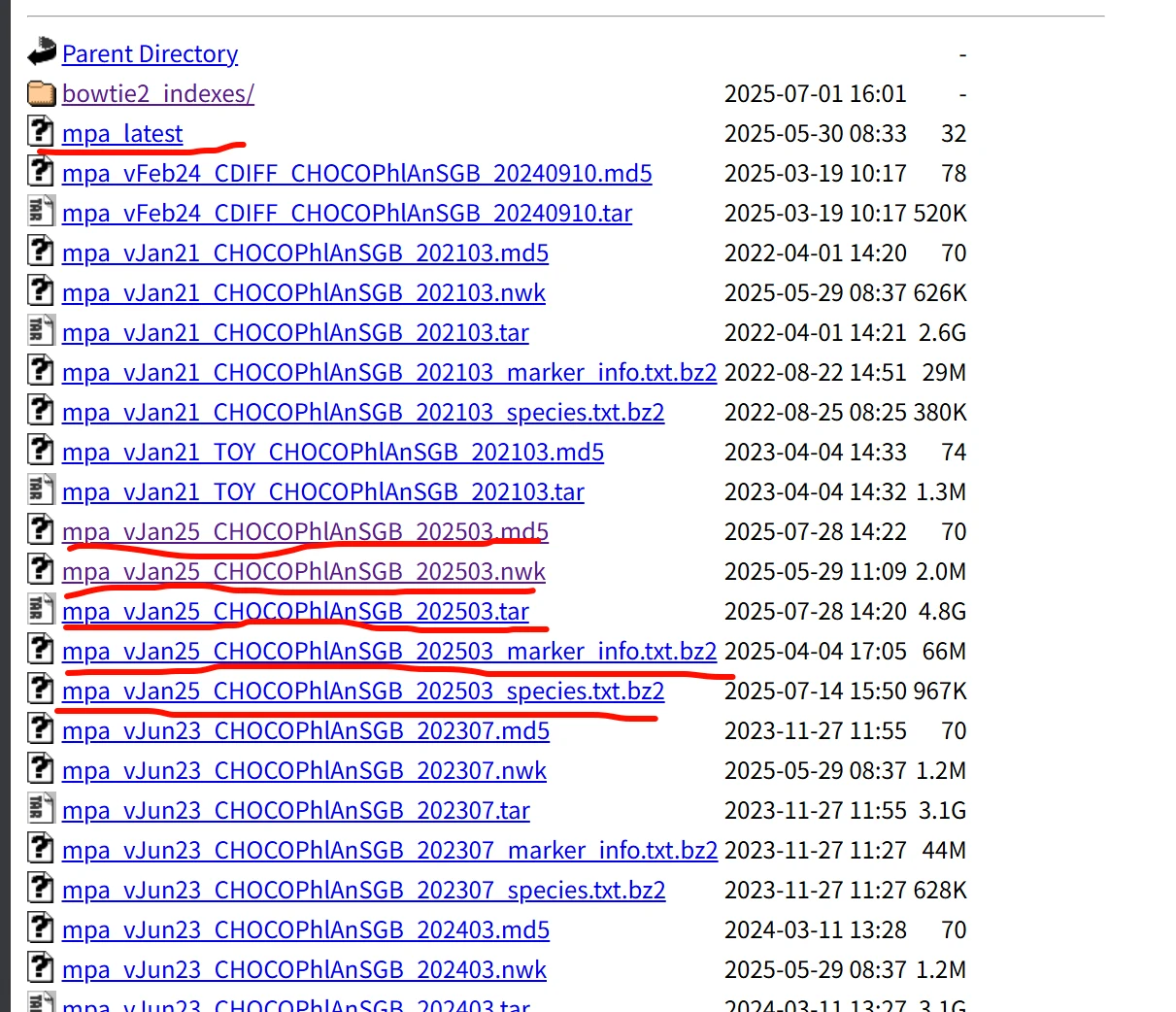
这是最麻烦的一步(一般用这个命令都安装不上),下载速度较慢且总共20多G,建议去官网下载,下载最新的那个数据库。
有时候下载速度慢,可能引起失败,建议手动下载最新数据库:
地址在这里:http://cmprod1.cibio.unitn.it/biobakery4/metaphlan_databases/
下载这几个文件:
下载完成后将所有下载文件放入下面目录(根据自己安装目录找ananconda3的位置,后面路径都一样):
anaconda3/envs/mpa/lib/python3.7/site-packages/metaphlan/metaphlan_databases
后面第一次去运行metaphlan去注释你的序列的时候会自动建库
也可以放到自己设定的专用数据库目录/mnt/metaphlan4_db,然后在使用软件的时候指定数据库的目录。
这几个文件全部都要放在metaphlan_databases这个文件夹里面,路径一般是这个:
path/to/anaconda3/envs/mpa/lib/python3.7/site-packages/metaphlan/metaphlan_databases
注意我前面这个path/to/是大家放anaconda3的文件路径。
注意mpa_latest这个文件,如果您没有的话,可以自己vim写一个,里面的内容也就是下载的数据库的名字:
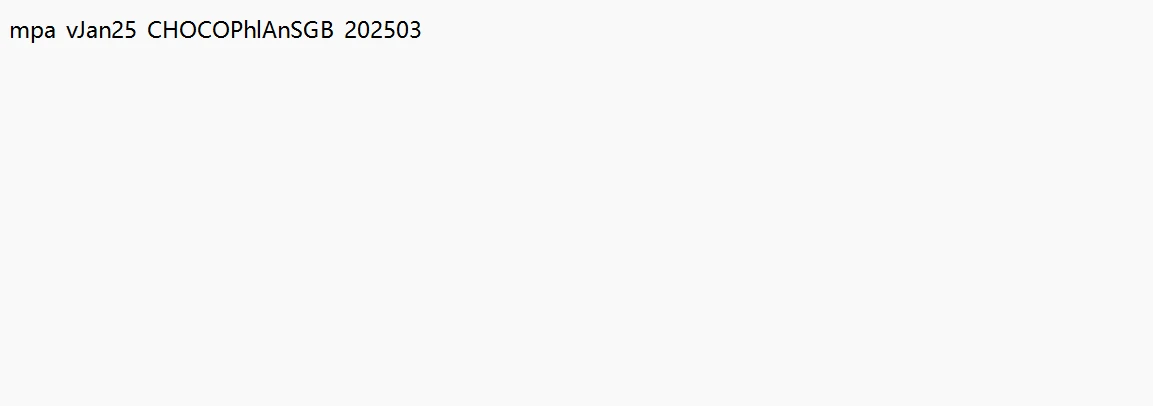
后面运行metaphlan4跑一个数据就会自动建库。建库后的metaphlan_databases就有这些文件。
四、运行
单端数据:
time metaphlan \
--input_type fastq \
--output_file AT1a1.txt \
--nproc 160 \
--tmp_dir ./metaphlan_tmp_dir \
--db_dir /public/home/huser076/db/metaphlan4_db \
./seq/AT1a1_1.fq.gzmetaphlan ./seq/AT1a1_1.clean.fq.gz,AT1a1_2.clean.fq.gz --input_type fastq -o AT1a1.txt --nproc 30 --stat_q 0.1 --bowtie2out bowtie2out_AT1a1.bz2
双端数据:
time metaphlan \
-1 ./seq/AT1a1_1.fq.gz \
-2 ./seq/AT1a1_2.fq.gz \
--input_type fastq \
--output_file AT1a1_double.txt \
--nproc 160 \
--tmp_dir ./metaphlan_tmp_dir \
--db_dir /public/home/huser076/db/metaphlan4_db \
--subsampling_paired 0注意fastq1和fastq2之间有个逗号。
其中参数的含义:
–input_type输入数据类型
–stat_q越低假阳性率越高,默认是0.2,但是可以按照数据具体情况调整,0.1应该是可以接受的
–nproc线程数
五、数据合并截取
多个数据运行完成后,需要对多个结果进行合并(不同版本的数据不能合并) :
merge_metaphlan_tables.py metaphlan_output*.txt > output/merged_abundance_table.txt
#筛选出不同水平物种丰度表格
grep -E ‘(s__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘t__’|sed ‘s/^.*s__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_species.txt
grep -E ‘(g__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘s__’|sed ‘s/^.*g__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_genus.txt
grep -E ‘(f__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘g__’|sed ‘s/^.*f__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_family.txt
grep -E ‘(o__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘f__’|sed ‘s/^.*o__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_order.txt
grep -E ‘(c__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘o__’|sed ‘s/^.*c__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_class.txt
grep -E ‘(p__)|(clade_name)’ merged_abundance_table.txt |grep -v ‘c__’|sed ‘s/^.*p__//g’|sed ‘s/\ \ /\ /g’|sed ‘s/\ /\t/g’ > merged_abundance_table_phylum.txt
六、脚本
大家可以一个一个数据的跑,当然也可以写个循环,这样效率更高,这个是小果自己写的一个最简单的shell脚本:
for i in `ls data/split`; do
metaphlan data/${i}_1.fq.gz,data/${i}_2.fq.gz –input_type fastq –nproc 30 –output metaphlan/${i}.txt –bowtie2out metaphlan-1/${i}.bowtie –stat_q 0.05; done
###split文件夹里面是所有数据名称的文件
运行完的结果大概是这样:
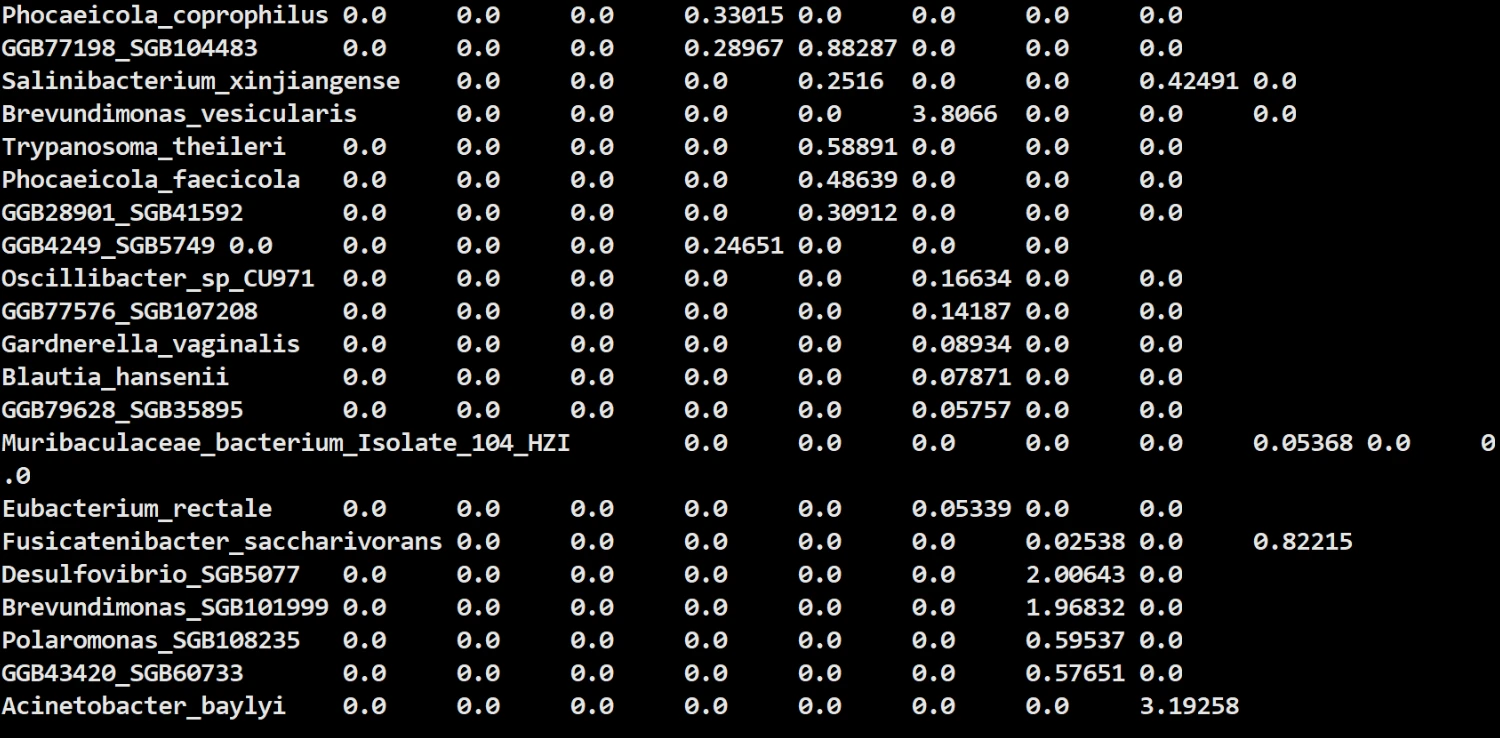
这就是本次教程的全部内容啦,后续小果会为大家带来更多的宏基因组和扩增子软件的使用教程。
参考地址:MetaPhlAn 4—宏基因组物种注释工具 – 云生信
202310-宏基组学物种分析工具-MetaPhlAn4安装和使用方法-Anaconda3- centos9 stream-CSDN博客
MetaPhlAn 4—宏基因组物种注释工具

超全常用 conda 命令整理
Win10/11系统通过WSL2方式将Ubuntu20.04安装到D盘的简洁方式