绘制分组的字母差异标记的柱状图
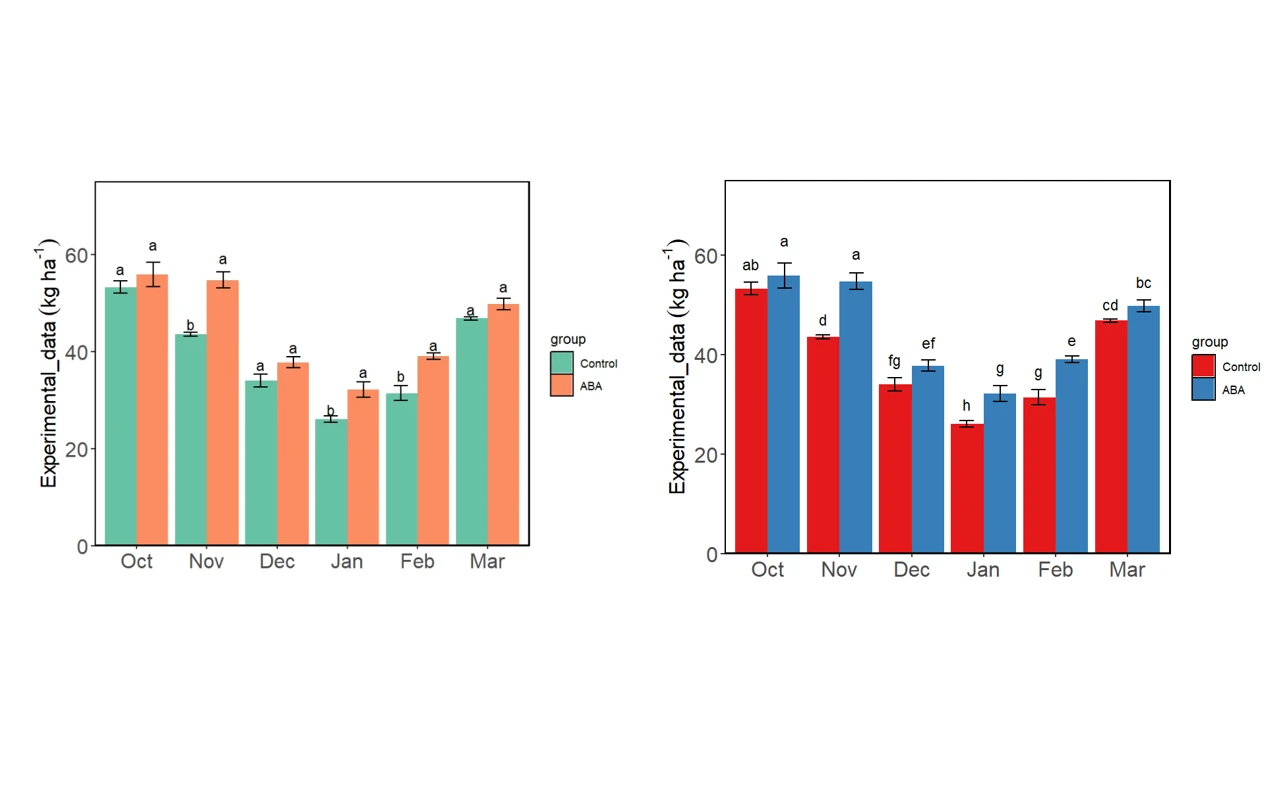
包括了组间的差异比较和所有样本的差异比较的两种字母标记方式
代码如下:
library(openxlsx)
###批量显著性检验及作图
library(agricolae)
library(tidyverse)
library(tidyr)
# 读取数据
dat <- read.xlsx("D:/00_Software/03_Coding/python_Project/GUI_Leaning/QT6/07program/python_script/example_data/bar_plot_grouped_data.xlsx",
sheet = 1) # 使用索引2来指定第二个工作表
dat_group = read.xlsx("D:/00_Software/03_Coding/python_Project/GUI_Leaning/QT6/07program/python_script/example_data/bar_plot_grouped_data.xlsx",
sheet = 2)
names(dat)[1] <- "Group" # 重命名列名
names(dat_group)[1] <- "SampleID" # 重命名列名
names(dat_group)[2] <- "group" # 重命名列名
dat_long <- dat %>%
pivot_longer(
cols = -Group, # 排除Group列,将其他所有列转换为长格式
names_to = "SampleID", # 新的列名变量
values_to = "value", # 新的值变量
names_prefix = "" # 移除列名前的前缀
)
# 将分组信息与长格式数据合并
dat <- dat_long %>%
left_join(dat_group, by = c("SampleID"))
# 设置因子水平,原因是后续作图的柱子排序问题 手动设置因子的水平
# dat$Group <-factor(dat$Group,level=c("Oct","Nov","Dec","Jan","Feb","Mar"))
# dat$group <-factor(dat$group,level=c("Control","ABA"))
# 确保作图的分组是因子水平,且按照原来的顺序
dat$Group <- factor(dat$Group, levels = unique(dat$Group))
dat$group <- factor(dat$group, levels = unique(dat$group))
##分组求均值(分组顺序至关重要)
dat_mean <- dat %>%
group_by(Group, group) %>%
dplyr::summarize(mean_data = mean(value, na.rm = T), SD = sd(value, na.rm = T),
n=sum(!is.na(value)), SE = SD/sqrt(n)) # 保持group的原始顺序========
##给均值添加显著性检验结果
Group <- unique(dat$Group)
out.1 <- data.frame()
for (i in Group){
# 下面这个if语句可以解决某些特殊情况的数据缺失
print(i)
data <- filter(dat, Group == i)
#选择最小显著差异法,可修改======================================================
test <- LSD.test(lm(value ~ group, data), 'group', console = T, alpha = 0.05)
data1 <- data.frame(test$groups, Group = i)
data11 <- cbind(group = row.names(data1), data1)
out.1 <- rbind(out.1, data11, make.row.names = F)
}
#将结果返回分组均值数据框
dat_mean <- merge(dat_mean, out.1, by = c('Group','group'))
# 删除value一列的值
dat_mean <- subset(dat_mean, select = -value) # 删除value列
# 为了后面的整体显著性分析,需要将Group_groupd列转换为因子类型
# 下面是创建一个新的列来标记每一个小分组的名称,用于后面的整体显著性分析
dat <- dat %>%
mutate(Group_group = factor(paste0(Group, "_", group)))
# 在data——mean中创建:
dat_mean <- dat_mean %>%
mutate(Group_group = factor(paste0(Group, "_", group)))
# 先将LSD方法注释一下
##给均值添加显著性检验结果
LSD_test_Group_group <- LSD.test(lm(value ~ Group_group, dat), 'Group_group', console = T, alpha = 0.05)
# Duncan_test_Group_group <- HSD.test(lm(pod ~ Group_group, dat), 'Group_group', console = T, alpha = 0.05)
data2 <- data.frame(LSD_test_Group_group$groups)
colnames(data2)[2] <- "mark_Group_group" # 重命名这一列的列名,避免和上面的那个重复
# 下面的一行代码可以将索引的行名称提取一列到列表
data22 <- cbind(Group_group = row.names(data2), data2) #添加行名一列,指定列名Group_group
#将结果返回分组均值数据框
dat_mean <- merge(dat_mean, data22, by = c('Group_group'))
# 删除value一列的值
dat_mean <- subset(dat_mean, select = -value) # 删除value列
# 基础绘图----
p = ggplot(dat, aes(Group, value, fill = group)) +
# facet_wrap(~Group, ncol = 3) + # 做个分面图
stat_summary(position = position_dodge(width = 0.6),
geom = 'col',
fun = mean,
width = 0.5,
color = 'black',
alpha = 1
)
# 初始的主题----
p = p + theme_classic() # 设置经典的主题
# 柱子颜色设置
p = p + scale_fill_brewer(palette = 'Set1')
# 样本点----
p = p + geom_point(data = dat, aes(y = value),
position = position_jitterdodge(),
alpha = 0.5,
size = 2,
shape = 21,
color = 'black',
stroke=0.8)
# 误差棒----
p = p + stat_summary(fun.data = 'mean_se', geom = 'errorbar',
position = position_dodge(0.6), width = 0.4, size = 0.5)
# 字母标记----
p = p + geom_text(data = dat_mean, aes(y = (mean_data + SD)*1.03, x = Group, group = group, label = mark_Group_group),
position = position_dodge(0.6),
size = 4,
family = "serif" # 设置字体
)
fount_style_set = "serif" # 新罗马字体
# 100全局字体设置----
p = p+
theme(
text = element_text(family = fount_style_set,colour = 'black'), # 设置所有文本的字体
axis.text = element_text(family = fount_style_set,colour = 'black'), # 设置坐标轴文本的字体
legend.title = element_text(family = fount_style_set,colour = 'black'), # 设置图例标题的字体
legend.text = element_text(family = fount_style_set,colour = 'black') # 设置图例文本的字体
)
# 设置y轴最大值最小值----
p <- p + coord_cartesian(ylim = c(0, 65))+
scale_y_continuous(expand=c(0,0))
p = p + labs(x = NULL, y = expression(data~(`mg·m`^-3))) # 设置坐标轴标签
# 设置绘图区域的边距
# p <- p + theme(plot.margin = margin(0.5, 0.5, 0.5, 0.5, "cm")) # 设置绘图区域的边距
print(p)
# ggsave("C:/Users/law/Desktop/1相对含水量.pdf", p, width = 8, height = 5, dpi = 300)
THE END

R-4.4.1及R-studio保姆级安装配置详细教程及常见问题解答
前言
我不生产知识,我只是知识的搬运工,以下内容是源于 CSDN - 数模加油站 的安装教程:最新R(4.4.1)及R-studio保姆级安装配置详细教程及常见问题解答
个……

R语言中导出包内置数据集
前言
在数据分析和研究过程中,常常需要将R包中的内置数据集导出为外部文件,以便进行进一步的分析、共享或存档。本文将详细介绍如何在R中使用microeco包和ope……

OTU/ASV表抽平
1 抽平是什么?
抽平:指按照一定数量或样本序列最低数量,将所有样本的序列随机抽取至统一数据量。
简单地说,就是在不同的样本测序数据有差距的时候,保证样……
散点拟合作图
数据格式:
代码:
library(openxlsx)
library(ggplot2)
library(ggpmisc)
dat = read.xlsx("./散点拟合数据.xlsx",
sheet = 1,)
……