KEGG所有ko及对应通路整理
下载json文件
点击 这里 进入下载页面,右键从链接另存文件
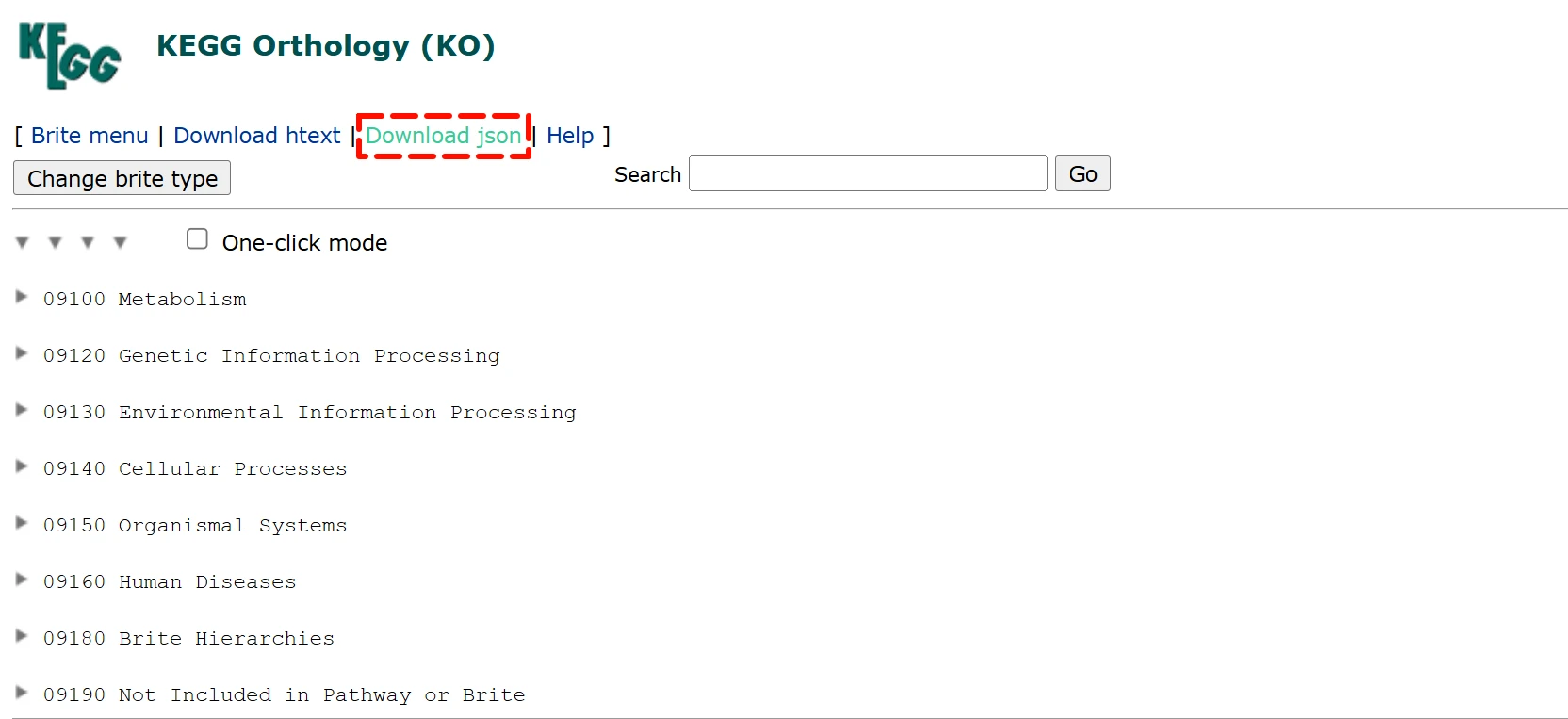
获得的json文件如图:

使用python处理json文件
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式,在python中可使用json包进行解码与编码,主要涉及四个方法:load, loads, dump, dumps。
json.loads:将json字符串解码为python对象
json.dumps:将python对象编码为json字符串
json.load和json.dump:分别与json.loads, json.dumps的功能对应,但需要传入文件描述符,对文件进行操作
import json
# 读入 JSON
with open('C:/Users/law/Desktop/ko00001.json', encoding='utf-8') as f:
data = json.load(f)
out_lines = []
# 递归函数
def walk(node, lvls):
"""
node : dict
lvls : list[str] 当前已累积的层级(最多 3 级:L1/L2/L3)
"""
name = node['name']
kids = node.get('children', [])
# 根据已累积层级决定下一步
if len(lvls) < 3: # 继续向下收集层级
for ch in kids:
walk(ch, lvls + [name])
else: # 已到叶子层,解析 KO
try:
ko, *desc = name.strip().split(maxsplit=1)
desc = ' '.join(desc) if desc else ''
ko = 'ko:' + ko if not ko.startswith('ko:') else ko
out_lines.append('\t'.join([ko] + lvls + [desc]))
except Exception:
pass
# 从根节点的第一层 children 开始
for child in data['children']:
walk(child, [])
# 写出 TSV
with open('C:/Users/law/Desktop/ko_pathway1.txt', 'w', encoding='utf-8') as f:
f.write('KO\tPathwayL1\tPathwayL2\tPathwayL3\tKoDescription\n')
f.write('\n'.join(out_lines))整理好的kegg通路文件:

THE END
批量重命名文件名称(windows端)
前言
最近在整理微生物测序数据的时候需要重命名一下文件,但是一个文件夹中样本有太多了,因此在网上找到了一个批量重命名的方法,特此记录一下,防止以后需……
KEGG所有ko及对应通路整理
下载json文件
点击 这里 进入下载页面,右键从链接另存文件
获得的json文件如图:
使用python处理json文件
JSON (JavaScript Object Notation) 是一种轻量级……

UCAS / 懒人评教方法
前言
又到了一学期一次的课程教评环节,好像在每个大学都需要评教。在UCAS,不光要评价课程,还要评教师,这里记录一下一些已有的懒人方法,参考自一篇知乎文……

FAPROTAX功能注释
1.下载文件
访问http://www.loucalab.com/archive/FAPROTAX/lib/php/index.php?section=Home,下载Download板块最新软件包
2. 数据准备
文件格式的txt的文件……