EcoAmp中数据标准化方法介绍
EcoAmp软件中使用的标准化函数是 vegan 包中的 decostand 函数,下面是各个标准化方法的介绍:
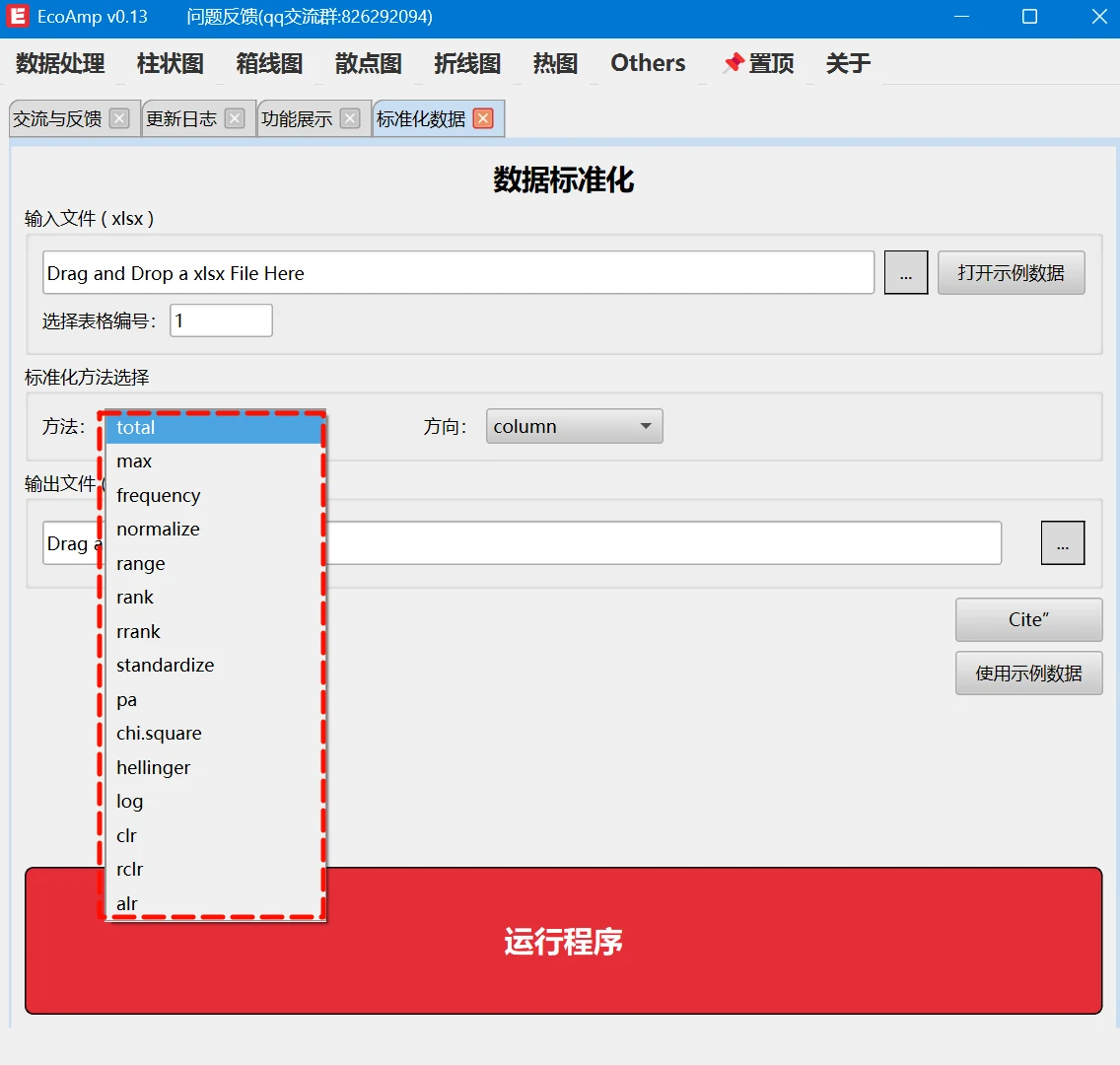
1. total
👉 按行(样本)或列(物种)的总和进行标准化。
-
公式:每个值 ÷ 该行(或列)的总和。
-
常用于将样本数据转化为相对丰度(百分比)。
2. max
👉 按行或列的最大值标准化。
-
公式:每个值 ÷ 该行(或列)的最大值。
-
结果范围是 0–1,突出每个样本中相对最高的物种。
3. frequency
👉 按行或列的总和标准化,再乘以非零元素个数。
-
目的是让非零值的平均数为 1。
-
常用于减少稀疏数据对计算的影响。
4. normalize
👉 使得行(或列)的平方和等于 1。
-
类似向量归一化,每行看作一个向量,强调整体形状而非绝对量。
-
多用于距离计算或余弦相似度分析。
5. range
👉 将数据缩放到 [0,1] 区间。
-
公式: (x−min)/(max−min)(x - \min) / (\max - \min)。
-
常用于不同变量量纲不一致时,进行统一比较。
6. rank
👉 用秩(排名)替代丰度值,零保持为零。
-
例如:最小值=1,次小值=2,以此类推。
-
避免绝对数值的影响,突出相对顺序。
7. rrank
👉 与 rank 类似,但进一步转化为相对秩(最大值为 1)。
-
结果在 0–1 之间。
-
适合强调相对位置而非绝对丰度。
8. standardize
👉 进行标准化为零均值、单位方差。
-
公式: (x−μ)/σ(x - \mu) / \sigma。
-
常用于消除不同变量量纲和尺度的影响,类似 z-score。
9. pa
👉 转换为出现/缺失(presence/absence) 数据。
-
所有非零值变为 1,零保持为 0。
-
用于关注物种是否存在,而非丰度多少。
10. chi.square
👉 卡方标准化。
-
按行总和和列平方根加权,近似 correspondence analysis (CA) 中的卡方距离。
-
常用于群落数据的卡方相关性分析。
11. hellinger
👉 Hellinger 转换:对相对丰度(total 标准化后)再开平方。
-
公式: x/row sum\sqrt{x / \text{row sum}}。
-
特点:保留比例信息,同时减弱优势种的影响。
-
在物种丰度数据和欧氏距离结合时特别常用。
12. log
👉 对数据取对数(logb(x)+1\log_b(x) + 1,零保持为零)。
-
常见于降低高丰度物种的权重。
-
logbase控制对数底数,大底数更接近 presence/absence。
13. clr(centered log ratio)
👉 中心化对数比变换。
-
公式:clr(xi)=log(xi)−1D∑j=1Dlog(xj)\text{clr}(x_i) = \log(x_i) - \frac{1}{D}\sum_{j=1}^D \log(x_j)。
-
特点:去除组成型(compositional)数据的比例偏倚,常用于微生物群落数据。
-
需所有值 > 0,通常要加 pseudocount(如 +1)。
14. rclr(robust clr)
👉 鲁棒中心对数比变换。
-
与 clr 类似,但可以处理包含零的数据,不必加 pseudocount。
-
通过仅在正值上取几何平均来避免零值问题,并利用矩阵补全方法修复缺失值。
-
在高维稀疏微生物组数据中更稳定。
15. alr(additive log ratio)
👉 加性对数比变换。
-
公式:alr(x)=[log(x1/xD),log(x2/xD),...,log(xD−1/xD)]\text{alr}(x) = [\log(x_1/x_D), \log(x_2/x_D), ..., \log(x_{D-1}/x_D)],以某个参考物种/列作为分母。
-
常用于化学变量(如 pH)或多项式回归。
-
注意:会丢掉一个变量(参考列)。
📌 总结:
-
比例/丰度型:
total、hellinger、log -
秩序型:
rank、rrank -
标准化型:
normalize、standardize、range -
出现/缺失型:
pa -
组分数据(compositional data):
clr、rclr、alr -
特定分析专用:
chi.square、frequency
在苹果系统电脑中安装最新版本EcoAmp
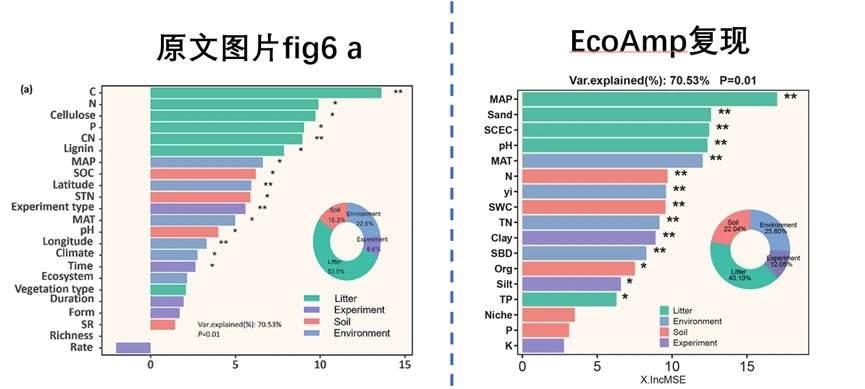
随机森林分析+绘图教程
EcoAmp中数据标准化方法介绍